
Tijdens Conversion Hotel 2017 heb ik twee presentaties van CRO godfather Ronny Kohavi mogen bijwonen. Eén van de dingen die hij meerdere malen heeft benoemd is het controleren of er een Sample Ratio Mismatch (SRM) is bij je experimenteren. Hij deelde op Twitter een Excel bestand met de formule en sindsdien check ik hiermee alle experiment-resultaten.
Ik heb de check toegevoegd aan mijn geautomatiseerde experiment analyse google sheet en maanden na het gebruiken van de formule ben ik geen SRM error tegengekomen, alles was Gucci ✓
Totdat het zich wel weer voordeed…
Ik wist niet wat ik moest doen en of ik de resultaten kon vertrouwen. Dit artikel zal voorkomen dat je dezelfde zoektocht naar antwoorden moet afleggen. Ik geef kort antwoord op de volgende vragen:
- Wat is een Sample Ratio Mismatch?
- Hoe analyseer je de oorzaak van een SRM?
- Wat is het effect van een SRM op je experiment-resultaat en in welke prullenbak kunnen de resultaten?
Wat is een Sample Ratio Mismatch?
Bij een Sample Ratio Mismatch komt de steekproefverhouding niet overeen met het ontwerp van een experiment. De verdeling tussen control en variant is nooit exact 50/50 en met een SRM-check controleer je of dit verschil komt door toeval of niet. In het onderstaande voorbeeld is er een Sample Ratio Mismatch:

Hoe werkt een SRM-check nou precies?
Een SRM-check berekent de P waarde van een Experiment door middel van een T- en/of een Chi-square-test. De P waarde geeft aan of het bezoekersverschil wel of niet op toeval berust. Hierbij is de randvoorwaarde een P waarde onder de 0,001. Dit betekent dat er met een zekerheid van 99,9% gezegd kan worden dat het verschil niet op toeval berust en dat er iets is fout gegaan.
Een SRM-check doe je op totaalniveau maar ook binnen segmenten. Er kunnen, bijvoorbeeld door een bug, veel meer Google Chrome bezoekers in de control groep zitten t.o.v. de variant. Een SRM wordt veroorzaakt door een technische fout en daarom analyseer je de segmenten waarbij je deze fouten verwacht. De bezoekerssegmenten die ik analyseer zijn:
- Nieuw en terugkerend
- Desktop, tablet en mobiel
- Alle browsers
- Alle kanalen
- Alle domeinen
Hoe analyseer je de oorzaak van een SRM?
Bij een SRM is er een fout waardoor de bezoekersverdeling scheef is. Dit kun je op 5 manier onderzoeken:
1. Een stap voor het experiment gaat iets fout
- Een email campagne stuurt alleen bezoek naar control.
- Op de pagina voor het experiment is een aanpassing gemaakt wat voor minder bezoekt zorgt bij control of de variant.
2. Onderzoek hoe bezoekers worden verdeeld
- Worden de bezoekers per domein gelijk verdeeld of worden domeinen genegeerd?
- Hoe werkt de verdeling van bezoekers als er veel verschillende experimenten live staan. Zijn de bezoekers die verschillende experimenten gezien hebben gelijk verdeeld over andere experimenten?
3. Onderzoek de gehele data pijplijn
- De laadtijd van analytics in een variant duurt iets langer t.o.v. control waardoor snelle bezoekers de pagina al hebben verlaten voordat je analytics pakket is geladen.
- Worden bots in control en de variant hetzelfde gefilterd?
4. Sluit de beginperiode van het experiment uit
De controle of de variant is iets later gestart. Hierdoor heeft een van de varianten al bezoekers ontvangen terwijl de andere nog niet live staat. Dit kan je uitsluiten door het eerste uur of dag uit te sluiten van je analyse.
5. Analyseer verschillende segmenten
Als je een segment vindt waarbij zich een SRM voordoet, kun je beter begrijpen wat het verschil heeft veroorzaakt. Analyseer de segmenten waar je een verschil verwacht:
- Analyseer de resultaten per dag
- Analyseer verschillende browsers en browservarianten
- Analyseer verschillende domeinen
- Analyseer voor jou relevante segmenten
Wat is het effect van een SRM op je experiment-resultaat
Stel dat in de variant een specifiek segment het heel goed doet t.o.v. control en dat deze bezoekers veel vaker aanwezig zijn in de variant t.o.v. control. Dat specifieke segment is dan oververtegenwoordigd en vergroot het positieve effect. Als het segment te weinig aanwezig is in de variant, dan wordt het effect van het segment juist verkleind omdat het ondervertegenwoordigd is.
Zie hieronder een voorbeeld waarbij in control 52% nieuwe bezoekers zijn en in de variant 48%, een ondervertegenwoordiging van nieuwe bezoekers in de variant t.o.v. control.
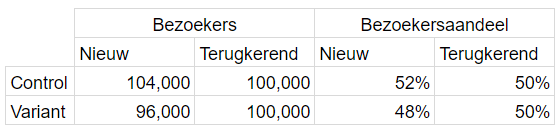

Het experiment lijkt een winnaar maar de conversieratio’s voor nieuwe en terugkerende bezoekers zijn exact hetzelfde. Door de ondervertegenwoordiging van nieuwe bezoekers in de variant lijkt het alsof er een conversieratio toename is.
In welke prullenbak kunnen de resultaten?
Afhankelijk van de grote van de sample ratio mismatch zijn er twee opties:
- Recyclen: de Sample Ratio Mismatch is te groot. Je hebt besloten dat de overgebleven groep te klein is en de resultaten zijn niet valide. Je weet hopelijk wel waardoor de SRM wordt veroorzaakt en je gaat het experiment recyclen in de hoop dat als het de volgende keer live staat er geen problemen zijn.
- Niet weggooien: de Sample Ratio Mismatch wordt veroorzaakt door een kleine specifieke groep bezoekers die je hebt uitgesloten van de analyse. Het is zonde om alle resultaten weg te gooien maar neem het resultaat met een korreltje zout. Het is niet representatief omdat de uitgesloten specifieke groep mist.
Idealiter fix je de bug en zet je het experiment opnieuw live, maar helaas is dit niet altijd mogelijk en dan is dit een optie.
Bronnen:
Advanced Topic van Microsoft experimentatie team: Guardrails metrics
Tweet https://twitter.com/ronnyk/status/932798952679776256?lang=en
Formule https://t.co/U9WdHUbPGL
Reacties (2)