
Bij het nemen van een sample, neem je feitelijk een stukje van iets wat representatief is voor het geheel. Bijvoorbeeld van een totale populatie of een volledige dataset met sessies van je website. Maar wat als je tijdens het analyseren van je A/B testen tegen een situatie aanloopt waarin je niet alle sessies kunt gebruiken omdat het resultaat gesampled wordt? Dan ga je op zoek naar alternatieven en oplossingen…
Wat is sampled data?
Wanneer je Google Analytics Standard gebruikt (dus niet de 360 versie) dan heb je zeker regelmatig met sampling te maken gehad. Sampling ontstaat wanneer je data gebruikt in een context waarin deze complexer en groter is dan ‘standaard’. Denk bij het complexer maken aan het gebruik van segmenten of door een secundaire dimensie toe te voegen in een rapportage. In zo’n situatie geeft Google Analytics in een percentage weer dat er een sample van het totaal wordt genomen. Dit kan variëren van heel hoog (bijv. 95%) tot juist een heel laag percentage (bijv. 35%). Hoe lager dit percentage, hoe kleiner de dataset en des te minder nauwkeurig (en betrouwbaar) het resultaat kan zijn.
Het maakt ook zeker uit welke versie van Google Analytics je gebruikt. De betaalde versie (Google Analytics 360) geeft je meer flexibiliteit maar zelfs dan moet je oppassen dat je niet te snel de dagelijkse resource quota API requests verbrandt wanneer je sampling in je data wil vermijden. Zeker wanneer het om business rapportages gaat die hiervan afhankelijk zijn.
Het verschil in sampling tussen Google Analytics Standard en 360 is gebaseerd op een threshold van 500K aan sessies op property level (GA Standard) ten opzichte van 100M sessies op view level (GA 360). Dit hangt ook allemaal weer samen met de complexiteit van de queries die je gebruikt. Hierover kun je meer lezen in dit artikel van Google.
Sampled data kun je prima gebruiken om inzichten te krijgen over high-level cijfers of wanneer je naar trends in je data kijkt. Er zijn diverse artikelen op het internet te vinden die beweren dat een rapportage gebaseerd op 15% van de website sessies nog steeds redelijk accuraat is (onder deze grens zeker niet meer!). Maar ook dit hangt af van de totale sample size die je hiervoor gebruikt.
Bij het uitvoeren van A/B testen ligt alles iets genuanceerder. De kleinste verschillen kunnen de uitslag al beïnvloeden maar het is ook belangrijk omdat we afhankelijk zijn van, en gebaat zijn bij, het detecteren van de kleinste verschillen in de data tussen de test varianten die je gebruikt.
Hoe kan ik sampling vermijden?
Er zijn twee manieren om sampling in Google Analytics Standard te vermijden. De meest eenvoudige manier is om over te stappen naar Google Analytics 360. Dit is meteen ook de meest onwaarschijnlijke omdat zoiets voor de meeste gebruikers toch een budgetkwestie is en dit niet zomaar te overbruggen valt.
Het beste alternatief is om gebruik te maken van kleinere datasets (bijvoorbeeld via de Google Analytics API add-on in combinatie met Google Sheets). Daarnaast zoek je tegelijkertijd naar het optimum van de API-queries zodat je uiteindelijk op een zo gunstig mogelijk percentage aan sampling uitkomt. Dit is dus een kwestie van uitproberen en kijken wat werkt.
Het opsplitsen van de data ligt weliswaar het meeste voor de hand, maar dit kan ook meteen een tijdrovende klus worden. Zeker wanneer je handmatig datasets moet gaan samenvoegen. Een tool zoals Supermetrics hanteert deze benadering ook en heeft dit proces meteen voor je geautomatiseerd. Query’s worden daar opgeknipt en via de Google Analytics API in Google Sheets ingeladen om deze vervolgens op dezelfde locatie weer bij elkaar te voegen. Alles met als doel om sampling te voorkomen. Dit werkt in de praktijk overigens niet altijd want er blijven situaties waarbij ook Supermetrics toch nog steeds gesamplede data blijft geven.
Hoe kun je omgaan met sampling in je A/B test analyse?
Bij het doen van A/B testen wordt doorgaans een maximale looptijd van vier weken aangehouden. In het geval van Google Analytics Standard is de kans heel groot dat je na een week (zeven dagen) al te maken krijgt met sampled data. Dit is de reden dat voor een analyse de testperiode meestal in vier losse perioden van een week wordt opgedeeld.
In de praktijk kom ik Google Analytics accounts tegen die redelijk veel traffic hebben zodat de data zelfs al binnen een week is gesampled, bijvoorbeeld na 4 of 5 dagen. Voor die situatie heb ik mijn A/B test analyse verder geautomatiseerd door de testperiode niet in vier losse weken maar in 6 perioden van 5 dagen op te delen.
Overigens moet ik hier wel de volgende kanttekening bij maken: door de hoge mate van sampling (én de 6 losse perioden) gebruik ik in dit geval sessie-segmenten die gebaseerd zijn op de session-metric en niet de user-metric die ik doorgaans hiervoor gebruik (omdat je mensen wil beïnvloeden met de test). Dit heb ik gedaan om te voorkomen dat er in de test-analyse te veel unieke bezoekers per periode worden opgeteld. Immers, je wil het aantal unieke bezoekers over de hele testperiode weten en niet het aantal opgeteld per week. De kans bestaat dan dat je in je analyse onder de streep één enkele bezoeker niet 1 keer meetelt maar meerdere keren (max. 6 keer). Aangezien elke (unieke) bezoeker wel altijd een sessie met de website heeft kun je de sessies wel bij elkaar optellen.
A/B test analyse sheet
Hieronder een uitgelicht gedeelte van een A/B test analyse sheet waarbij je de test varianten, pagina, doel en looptijd (door alleen de begindatum in te vullen) kunt instellen .
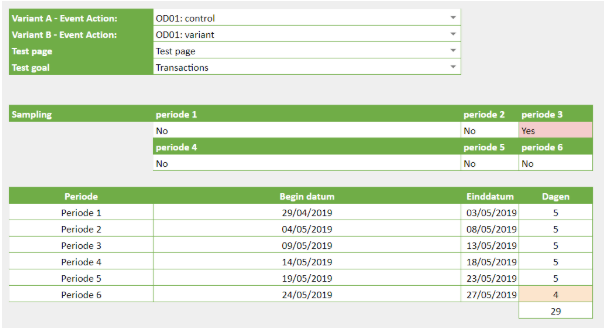
Mocht na het uitvoeren van het rapport in een periode toch onverwachts sampling optreden dan heb ik de mogelijkheid ingebouwd om met de sampled data te gaan schuiven en deze over de looptijd van 4 weken ‘te verdelen’.
In het voorbeeld hierboven treedt in periode 3 al binnen vijf dagen sampling op. Door het aantal sessies in periode 3 te verlagen van standaard vijf naar drie dagen wordt het aantal sessies in periode 6 automatisch verhoogd van vier naar zes dagen.
In het voorbeeld hieronder zie je dat er door de wijziging geen sampling meer optreedt en de A/B analyse gebaseerd wordt op 100% van de website sessies.
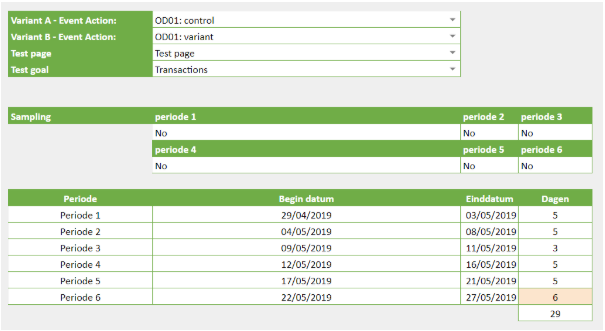
Tot nu toe heeft deze benadering een aantal situaties eenvoudig voor mij opgelost. Mocht er in meerdere perioden tegelijk sampling ontstaan, dan zou je ervoor kunnen kiezen de data verder of anders over de 6 (of meer) perioden te gaan verdelen, maar tot nu toe was dit niet nodig.
Heb je zelf ideeën hoe je dit beter zou kunnen aanpakken of nog verder zou kunnen optimaliseren? Laat dan hieronder een comment achter.