
Steeds vaker zie ik organisaties overstappen op Snowplow Analytics: een raw-data analytics platform volledig in eigen beheer.
Toen het tijd was om zelf op zoek te gaan naar een nieuw dataplatform kon ik er niet meer omheen. Ik zocht uit wat de tool mij allemaal beloofde, welke ervaringen andere mensen hadden met de tool en al snel was de keuze duidelijk.
Omdat de tool nog niet bij iedereen bekend is en er door de vele mogelijkheden die het platform biedt ongelofelijk veel verschillende toepassingen zijn, wil ik graag mijn ervaringen delen over de tool.
Wat is Snowplow Analytics?
Snowplow Analytics is een dataplatform dat volledig draait in je eigen cloud omgeving (Amazon of Google). Het bestaat geheel uit losse open source componenten die samen een analytics pijplijn / datasysteem vormen waar je mee aan de slag kan.
Het is gemaakt om data op een transparante manier te verzamelen, verrijken, sorteren en op te slaan, zodat je er mee kan doen wat je wil.
Tot zo ver klinkt het heel algemeen, en dat is het ook 🙂
Maar gelukkig voor de webanalisten onder ons: Je krijgt er in de basis tools en trackers bij die gericht zijn op het verzamelen en verwerken van web en app data. Dit gebeurt in 5 stappen, die ik zo dadelijk zal beschrijven. Maar eerst:
Wat is het niet?
Snowplow is geen kant en klare tool met alles er op en er aan. Als Snowplow “klaar” is met je data, is deze opgeslagen in een database, of komt deze uit in een data-pijplijn waar je je eigen applicaties op kan aansluiten.
Geen mooie plaatjes of grafieken dus. Je zal je data eerst moeten aanbieden aan Tableau, Looker, Google Datastudio, of een andere tool.
Kortom: je kan er alles mee, maar je moet er wel wat voor doen.
Hoe loopt data door Snowplow Analytics?
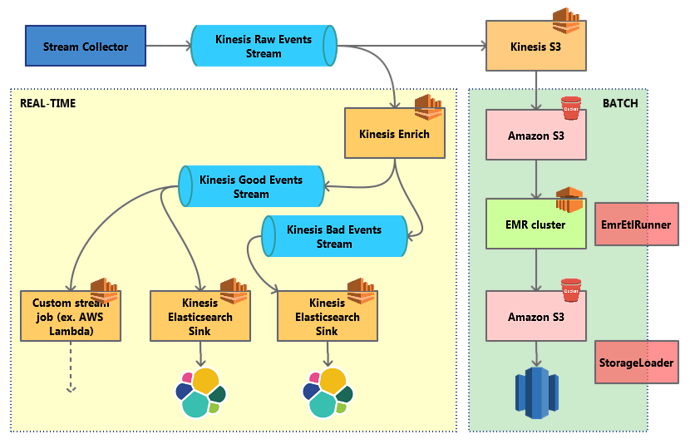
Snowplow Data pipeline
Stap 1: Data opsturen en verzamelen
Via trackers op web, app, embedded devices of via statische pixels kan je data richting de Snowplow collector schieten.
Tot zover niet veel bijzonders, want zo werken veel Analytics tools. Wel heb je bij het verzamelen de keus tussen de “batch” variant en de “real time” variant. Kies je de laatste, dan stroomt je data via een Amazon Kinesis of Apache Kafka pijplijn verder het systeem in.
Stap 2: Sorteren en verrijken
De opgestuurde data wordt niet meteen verwerkt: eerst moet hij gesorteerd en verrijkt worden. Hierbij is de configuratie heel rigoreus: er wordt alleen data geaccepteerd die “goed gevormd” is volgens jouw specificatie.
Verplicht veld vergeten (bv. “productID” is leeg)? Tekst opgestuurd in plaats van een nummer? Jammer, dan wordt deze hit opzij geschoven en niet verwerkt.
Voordeel: Je kan fout getaggede events snel opsporen en de data die je hebt is altijd wat het moet zijn (qua vorm dan).
Het verrijken van je data behoort tot dezelfde fase. Zo kunnen IP adressen worden geanonimiseerd, UserAgent strings omgezet naar iets leesbaars, en campagneparameters worden uitgelezen. Ook hier krijg je een hoop “enrichments” meegeleverd, allemaal gericht op webanalyse. Uiteraard kan je ook je eigen verrijking doen in deze fase, door bijvoorbeeld een API te koppelen.
Stap 3: Opslaan
Als de opgestuurde “hits” keurig zijn gechecked en verrijkt, is de data klaar voor opslag. Standaard opslagpunten die je kan kiezen zijn o.a. Postgres, Amazon Redshift, of Snowflake. Dit werkt zo:
- elke “hit” krijgt een eigen regel in de “
atomic.events” tabel. Afhankelijk van de tracker, zijn hier veel kolommen ingevuld met informatie: referrer, campagnes, user ID, sessie ID, URL, etc, etc. - afhankelijk van het type “hit”, kan er nog extra informatie worden opgeslagen in een gekoppelde tabel. Bijvoorbeeld “
atomic.nl_veilingsite_biedingen“, waar per hit kolommen in staan over de product, vraagprijs, huidige bod, nieuwe bod, looptijd, etc.
Deze “atomic” tabellen zijn de “feiten” waar je mee verder kan. Snowplow noemt het: “un-opinionated event data“. Wat je daarna gaat doen, is je eigen logica en regels toevoegen. Dat doe je in de modelleer-stap.
Stap 4: Je eigen model
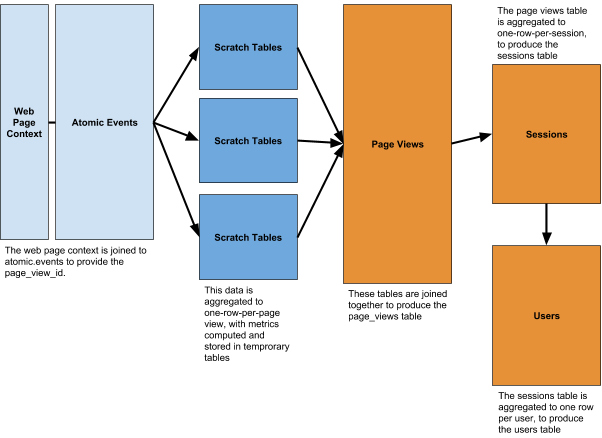
Web model van Snowplow
Tools als Google Analytics en Adobe Analytics hebben een “web model” ingebouwd wat al helemaal klaar is, en uitgebreid kan worden met custom dimensies, props, en maatwerk metrics. Bij Snowplow kan je een basis web model gebruiken wat hierop lijkt. En omdat je precies ziet hoe het model werkt, kan je het ook tot in het kleinste details tweaken, omvormen en uitbreiden naar je wensen.
Maar een “web model” hoeft niet per se. Stel je hebt een veiling-website. Dan ben je wellicht minder geïnteresseerd in pageviews (wat er bekeken wordt), maar meer in biedingen, bedragen en afteltijden.
In Google Analytics moet je de gebeurtenissen op je site kneden naar een “pageview“, “virtual pageview“, “event category“, of “productclick“. In Snowplow, kan je een maatwerk event opsturen wat precies is wat het is:
- Event: “bod”
- Properties: product, vraagprijs, huidige bod, nieuwe bod, resterende tijd
Deze maatwerk events komen in een eigen database tabel te staan, en hiermee kan je (in SQL) je eigen model maken, zodat je de goede entiteiten op de goede manier bij elkaar optelt, en je analyses kan doen die passen bij de logische structuur van de data zelf.
Voorbeeld van de veilingsite: in het model kan je metrics maken als:
- verschil van bod met uiteindelijke verkoopprijs
- aantal biedingen per gebruiker, per item, in het laatste uur, etc
En dimensies als:
- onder/boven de vraagprijs
- bodnummer
Deze dimensies en metrics hoef je dus niet alvast mee te sturen, maar kan je achteraf modelleren op basis van de bouwblokken.
Uiteraard kan je in deze fase niet alleen de door Snowplow verzamelde data gebruiken, maar je kan elke tabel uit je database betrekken. Handig als je de procuct-data ook in een database hebt staan: dan kan je die details ook gebruiken in je model.
Stap 5: Analyseren

foto: (cc) https://flic.kr/p/27SCRSr
Bij een “kale” snowplow installatie heb je een gevulde database, meer niet. Als je er iets uit wil halen, zal je zelf je SQL queries moeten typen, of een visualisatie-query tool moeten aansluiten op je database.
Goede tools hiervoor voor mensen met een wat lager budget: Amazon QuickSight, Metabase, Redash, of R/Shiny.
In feite alles wat kan praten met Postgres of Redshift kan je gebruiken, en je hoeft geen data meer te verplaatsen, want het staat allemaal al op de goede plek.
Samenvatting en conclusie
Als je een data-collectie platform wil waarbij je alle data in eigen beheer hebt, onbeperkte toegang wil tot de ruwe data, en heel flexibel wil zijn in het type data dat je verzamelt (lees: je wil meer meten dan pageviews), dan kan Snowplow een goed alternatief of aanvulling zijn op “de grote twee”, Google en Adobe.
Nadeel: er is kennis nodig, zowel van data architectuur en devops, als van data ontsluiting. Met de kant en klare suites die Adobe en Google bieden, zal je waarschijnlijk sneller een eerste resultaat hebben. Daar zijn de simpele dingen zeer eenvoudig.
Zelf aan de slag?
De doe-het-zelf variant van Snowplow is open source, en als je een devops team hebt met verstand van AWS, kan je zo aan de slag. Heb je wat minder van die kennis in huis, dan biedt Snowplow (het bedrijf) diverse vormen van managed services aan.
Zelf heb ik ooit deze blogpost van Simo Ahava gevolgd, die is helemaal compleet. Voor enkele tientjes per maand aan AWS kosten heb je dan je eigen werkende Snowplow omgeving.
Verdere links:
- snowplow code en handleidingen op github
- het open source snowplow web model
- het community forum
- snowplow meetups
Wat zijn jouw ervaringen met Snowplow?
Zelf ooit gewerkt met Snowplow? Laat het je vakgenoten weten in de comments. Dank!
Reacties (1)