Eerder deze week vertelde ik waarom ik denk dat Splunk de toekomst is van data-analyse en web-analytics. Vandaag deel ik mijn eigen ervaringen met Splunk, en volgende week leg ik uit hoe je zelf met Splunk aan de slag kunt!
Wat heb ik zelf al gedaan met Splunk?
Het internet staat vol succesvolle toepassingen van Splunk, zie ook boekentips aan het onderaan dit artikel. Zelf heb ik de volgende analyses en visualisaties gedaan in Splunk. Ter inspiratie voeg ik ook de Splunk search commando’s toe. voor de syntax van deze ‘zoekopdrachten’ (eerder gestapelde SQL), zie het gebruikersforum.
Tweet visualisatie: aantal tweets per sentiment per week
- Het trenden van positieve, negatieve en neutrale tweets over tijd (sentimentscore aangeleverd, Engelstalige sentimentanalyse wel beschikbaar in een app).
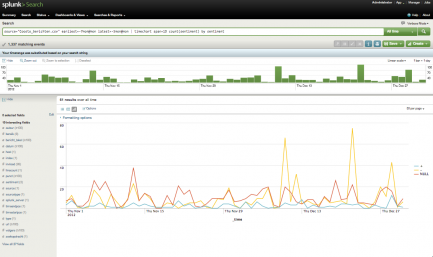
source=”Coosto_berichten.csv” earliest=-17mon@mon latest=-5mon@mon | bucket _time bins=400 | fillnull value=NULL
| eventstats count as total by _time
| stats count first(total) as total by _time, sentiment
| eval percent=(count/total)*100
| timechart span=3D first(percent) by sentiment
- Echte Big Data vraagt om het combineren van data-sets. Dit kan met een JOIN als de waarden in de kolommen van twee datasets gelijk zijn. Soms is dit echter niet het geval, zoals in onderstaande voorbeeld, waarin ik de plaatsnaam in een tweet wilde vertalen naar geo-coördinaten, zodat ik de Tweets op een kaart kon projecteren (oorspronkelijke Twitter geo-meta-data helaas niet beschikbaar). Dit doe je in Splunk met behulp van een LOOKUP tabel.
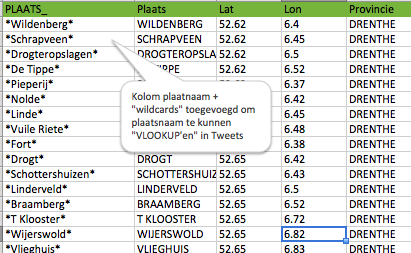
Voeg een kolom *plaatsnaam* toe (tbv “matching with wild cards”) aan een CSV met plaatsnamen en geo-coördinaten om met behulp van een LOOKUP tabel tweet-teksten te matchen met noorderbreedte en westerlengte (geo-coördinaten niet meegeleverd met tweets).
NB: bovenstaande tabel is dezelfde CSV tabel in Splunk
- Projecteer aantal tweets per regio op een kaart met behulp van de Splunk Google Maps app.
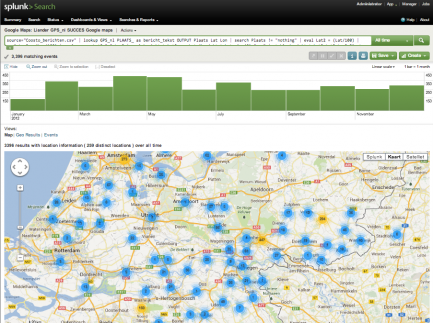
source=”Coosto_berichten.csv” | lookup GPS_nl PLAATS_ as bericht_tekst OUTPUT Plaats Lat Lon | search Plaats != “nothing” | eval Lat2 = (Lat/100) | eval Lon2 = (Lon/100) | eval _geo = Lat2+”,”+Lon2 | eval bericht_tekst2 = substr(bericht_tekst, 1, 40)+”…” | table bericht_tekst2 Lat2 Lon2 Plaats _geo
- Trends van tweets gefilterd op term (woord, hastag, plaats).
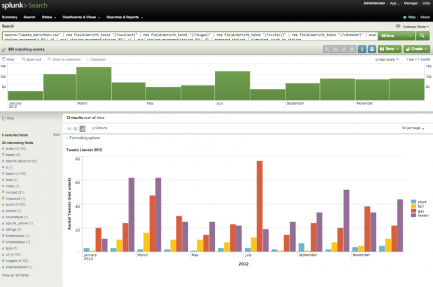
source=”Coosto_berichten.csv” | rex field=bericht_tekst “(?<a>elect)” | rex field=bericht_tekst “(?<b>gas)” | rex field=bericht_tekst “(?<c>fail)” | rex field=bericht_tekst “(?<d>meter)” | eval strings=mvappend(a,NULL,b) | eval strings=mvappend(strings,NULL,c) | eval strings=mvappend(strings,NULL,d) | mvexpand strings | timechart count by strings
Klik op de piek “tweets met gas in juli 2012″…
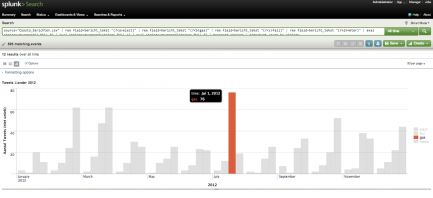
… en zie daar: de tweets – en groene balkjes per dag in juli – op het scherm!
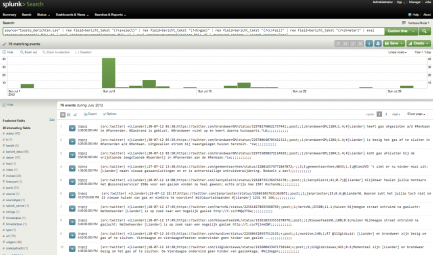
Trendplot (timechart) van CSV’s
Uit een webstatitiekenprogramma had ik CSV’s geimporteerd. Deze wilde ik in Splunk weergeven. Eén (groot) probleem: de CSV’s zelf bevatten helemaal geen informatie over welke tijdperiode het betrof, alléén de naam van iedere CSV bevatte informatie over de betreffende tijdsperiode. De CSV’s hadden wel een vaste naamconventie (weeknummer-jaar), waardoor ik met gebruik van een reguliere expressie (‘regex’) in één keer een hele ‘bulk’ CSV bestanden kon filteren en trenden.

sourcetype=”csv-*” | rex field=source “[\w\W]+PaWonen_Site_Paginas_wk(?\d{2})-12.csv” | search RABOBANK_URL_Path=”particulieren/producten/hypotheken/” | chart sum(Views) as “Pageviews (excl. opt-out)” over week
Wat ik nog meer heb gedaan met Splunk
- Inlezen van eigen tweets. Meer details volgen in een apart vervolgartikel: “zelf tweets verzamelen en analyseren.”
- Luisteren naar de 1% twitter stream “Fire hose”. Je zit binnen de kortste keren aan je data-limiet!
- Inlezen en analyseren RSS feed met behulp van de Splunk App.
- Plotten van aardbevingen door gebruik van de brondata van U.S. Geological Survey. Zie ook de Splunk blog: Splunking the earthquakes.
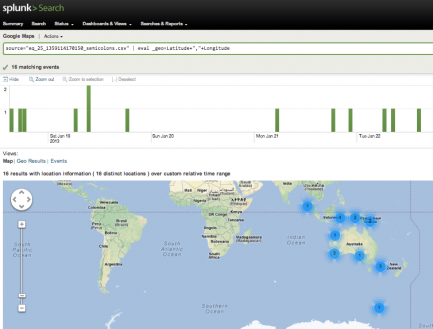
source=”eq_25_1359114170150_semicolons.csv” | eval _geo=Latitude+”,”+Longitude
Wil je weten hoe je zelf met Splunk aan de slag kunt?
Lees maandag deel 3!
Reacties (1)